一、grep 命令:文本搜索的 “瑞士军刀”
在 Linux 和 Unix 系统的广袤天地里,grep 命令宛如一把万能的 “瑞士军刀”,是文本处理领域的中流砥柱。无论是程序员在浩如烟海的代码库中追踪特定函数的调用,系统管理员于繁杂的日志文件里筛查错误信息,还是数据分析师从海量数据中挖掘关键线索,grep 都能迅速精准地定位到包含特定文本的行,将其从文本的海洋中打捞而出。想象一下,面对动辄成千上万行的代码,要找出所有引用特定变量的位置,手动翻阅无疑是天方夜谭。而 grep 只需一条简单指令,就能瞬间呈现结果。在数据分析时,从庞大的数据集文件里提取符合特定条件的数据行,grep 也能轻松搞定。可以说,它极大地提升了文本处理的效率,让数据的探索与掌控变得得心应手。但在某些精细的查找需求下,普通的搜索还不够,精确匹配的重要性愈发凸显,它能帮助我们直击靶心,找到最精准的文本内容。
二、什么是 grep 精确匹配
在 grep 的搜索功能里,精确匹配就如同给查找目标加上了精准定位的 “导航”。默认情况下,grep 进行的是模糊匹配,只要文本行中的某个部分包含了我们指定的字符或字符串,它就会把整行都筛选出来。这在某些宽泛的查找场景下确实有用,但当我们需要精确锁定特定的单词或短语时,模糊匹配就可能 “跑偏”。举个例子,我们有一个包含众多进程信息的文本文件,若只想找出名为 “httpd” 的进程,使用普通的 grep “httpd” 命令,可能会把 “httpd.conf”“apachehttpd” 等包含 “httpd” 字符的行也一并揪出,导致结果混杂。而精确匹配则要求目标文本必须是独立完整的单词 “httpd”,能完美避开这些误判,直击我们想要的关键信息,让搜索结果纯粹而精准,大大提升后续处理的效率。
三、常用的精确匹配参数
(一)-w 参数:单词匹配大师
在 grep 的众多参数中,-w 可谓是实现精确匹配的一把 “利器”。当我们在命令中加上 - w 后,grep 就如同一位严谨的单词匹配大师,只会把那些整个单词与我们指定模式完全一致的行筛选出来。比如说,我们手头有一个记录各种水果信息的文本文件,若想找出所有提到 “apple” 的行,直接使用 grep “apple”,可能会把 “pineapple”“crabapple” 等包含 “apple” 子串的行也一并捞出。但要是用 grep -w “apple”,那就大不一样了,它能精准定位到独立的 “apple” 单词所在的行,完美避开那些 “蹭热度” 的子串,让结果纯粹精准,帮我们直击关键信息。
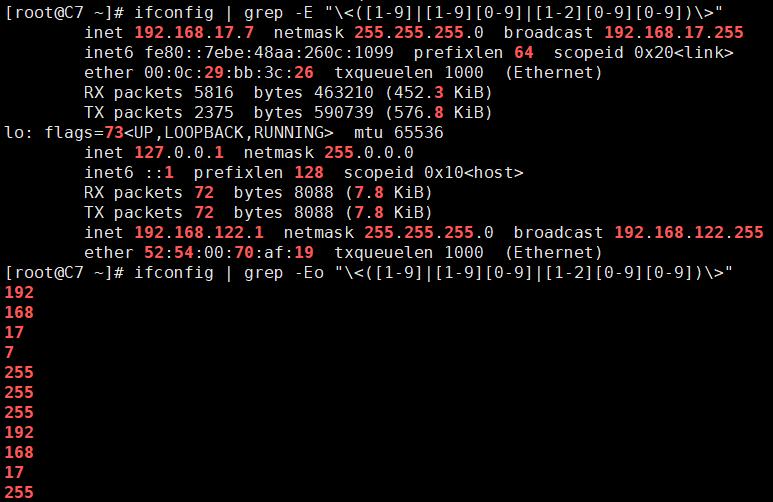
(二)“\<” 与 “\>”:边界限定神器
除了 - w 参数,“\<” 与 “\>” 这对组合也是精确匹配的得力助手。它们就像是给单词加上了隐形的边界框,能限定只匹配完整的单词,而非单词的一部分。以查找 “open” 单词为例,如果文本中有 “opening”“openly” 等词,单纯用 grep “open” 会把它们都找出来,可要是使用 grep “\<open\>”,就如同给 “open” 加上了专属结界,只有独立的 “open” 单词会被选中,在处理复杂文本、避免误匹配方面效果显著,为我们的文本搜索保驾护航。
四、实战演练:让精确匹配大
(一)代码文件中的函数查找
对于程序员来说,在代码的世界里穿梭时,grep 精确匹配是不可或缺的导航仪。假设我们正在研读一个用 C 语言编写的大型项目代码,想要快速定位到名为 “calculate_sum” 的函数定义。若简单使用 grep “calculate_sum” *.c,可能会把函数调用、注释里包含该字符串的行都找出来,让结果混乱不堪。但要是运用 grep -w “calculate_sum” *.c,就能精准地找到函数声明那一行,让我们直击函数定义源头。在 Python 项目中同样如此,当需要查找某个特定类的定义时,比如 “UserProfile” 类,执行 grep -w “class UserProfile” *.py,瞬间就能筛选出关键的类定义代码段,极大地提升代码阅读与调试的效率,让我们在代码丛林中不再迷茫。
(二)日志分析里的关键信息提取
系统管理员面对系统生成的海量日志时,grep 精确匹配就成了挖掘关键信息的 “神器”。以服务器日志为例,当服务器出现异常,我们急需找出错误源头。如果日志中记录着各种错误代码,使用 grep -w “ERROR404” access.log,就能迅速定位到所有出现 “ERROR404” 的行,知晓哪些请求遭遇了页面未找到的问题。再比如,要排查可疑的 IP 地址来源,执行 grep -w “192.168.1.” access.log,精确锁定来自该网段的访问记录,顺藤摸瓜,找出潜在的安全隐患,确保系统稳定运行,让运维工作事半功倍。
五、技巧与注意事项
(一)正则表达式配合:放大招
在 grep 精确匹配的进阶玩法里,正则表达式堪称 “秘密武器”,二者联手能解锁超多超强大的功能。正则表达式就像是一套精密的密码规则,能精准描述各种复杂的文本模式。比如说,当我们需要在文本中找出所有的电话号码,电话号码的格式通常是 “xxx-xxxx-xxxx” 这样的三段式结构,使用正则表达式 “[0-9]{3}-[0-9]{4}-[0-9]{4}” 与 grep 结合,像 “grep -E ‘[0-9]{3}-[0-9]{4}-[0-9]{4}’ file.txt”,就能迅速把符合格式的电话号码一网打尽。再比如匹配邮箱地址,利用正则 “[a-zA-Z0-9.%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,6}”,执行 “grep -E ‘[a-zA-Z0-9.%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,6}’ data.txt”,就能精准揪出所有邮箱,让我们在海量文本里精准定位关键信息,极大拓展了 grep 精确匹配的应用边界。
(二)字符转义:别踩坑
在使用 grep 进行精确匹配时,遇到特殊字符一定要小心 “陷阱”,像 “ 50” 这样的字符串,直接用 “grep ‘ ” 当成特殊的行尾锚定符号,导致匹配出错。正确做法是使用转义字符 “\”,输入 “grep ‘$50’ file.txt”,这样 “$” 就变回普通字符,能精准匹配到目标文本,避免因特殊字符含义混淆而得到错误结果,让搜索稳稳当当。
六、总结与拓展
通过本文的探索,我们已然领略到 grep 精确匹配在文本处理世界里的强大魔力。从基础概念的明晰,到 - w 参数、“\<” 与 “\>” 边界限定的巧妙运用,再到实战场景中代码查找、日志分析的 “大显身手”,以及正则表达式配合、字符转义等进阶技巧的掌握,每一步都是开启高效文本处理大门的钥匙。grep 精确匹配的征程远不止于此,这仅是踏入文本处理深邃天地的起始。读者们在日常工作学习中,应多多运用所学,于实践里打磨技能。不妨尝试将 grep 与其他命令联用,像搭配 sed、awk 等工具,解锁更复杂强大的文本处理连招;或是探索在不同操作系统环境下 grep 精确匹配的细微差异与独特应用,进一步拓展知识边界。持续钻研,终将在文本处理领域游刃有余,让数据探索之路愈发宽广顺畅。
